

Unsurprisingly, right here at Rewind, we’ve acquired a lot of facts to protect (more than 2 petabytes well worth). 1 of the databases we use is called Elasticsearch (ES or Opensearch, as it is at this time known in AWS). To put it simply just, ES is a document databases that facilitates lightning-quick look for results. Velocity is necessary when prospects are hunting for a specific file or product that they have to have to restore utilizing Rewind. Each and every second of downtime counts, so our research success have to have to be rapidly, precise, and reliable.
Another thing to consider was catastrophe recovery. As portion of our Program and Firm Controls Stage 2 (SOC2) certification system, we desired to ensure we experienced a doing work catastrophe recovery plan to restore assistance in the not likely occasion that the entire AWS area was down.

Protect your privacy by Mullvad VPN. Mullvad VPN is one of the famous brands in the security and privacy world. With Mullvad VPN you will not even be asked for your email address. No log policy, no data from you will be saved. Get your license key now from the official distributor of Mullvad with discount: SerialCart® (Limited Offer).
➤ Get Mullvad VPN with 12% Discount
“An complete AWS location?? That will by no means come about!” (Other than for when it did)
Anything is feasible, issues go completely wrong, and in order to meet up with our SOC2 specifications we essential to have a doing work alternative. Specially, what we essential was a way to replicate our customer’s details securely, efficiently, and in a expense-helpful way to an alternate AWS region. The remedy was to do what Rewind does so well – acquire a backup!
Let us dive into how Elasticsearch will work, how we utilized it to securely backup facts, and our recent disaster restoration method.
Snapshots
Initial, we are going to want a swift vocabulary lesson. Backups in ES are known as snapshots. Snapshots are saved in a snapshot repository. There are a number of kinds of snapshot repositories, such as 1 backed by AWS S3. Due to the fact S3 has the capacity to replicate its contents to a bucket in a further area, it was a best remedy for this distinct difficulty.
AWS ES comes with an automated snapshot repository pre-enabled for you. The repository is configured by default to choose hourly snapshots and you are unable to transform everything about it. This was a challenge for us for the reason that we required a each day snapshot sent to a repository backed by one particular of our own S3 buckets, which was configured to replicate its contents to an additional area.
 Listing of automated snapshots GET _cat/snapshots/cs-automatic-enc?v&s=id
Listing of automated snapshots GET _cat/snapshots/cs-automatic-enc?v&s=id
Our only selection was to produce and manage our possess snapshot repository and snapshots.
Preserving our have snapshot repository was not suitable, and sounded like a good deal of unnecessary do the job. We did not want to reinvent the wheel, so we searched for an present resource that would do the weighty lifting for us.
Snapshot Lifecycle Administration (SLM)
The 1st device we attempted was Elastic’s Snapshot lifecycle administration (SLM), a function which is explained as:
The best way to on a regular basis back up a cluster. An SLM coverage mechanically requires snapshots on a preset routine. The coverage can also delete snapshots centered on retention regulations you outline.
You can even use your own snapshot repository much too. Having said that, as quickly as we tried out to set this up in our domains it failed. We swiftly acquired that AWS ES is a modified version of Elastic. co’s ES and that SLM was not supported in AWS ES.
Curator
The subsequent tool we investigated is identified as Elasticsearch Curator. It was open up-resource and taken care of by Elastic.co themselves.
Curator is just a Python instrument that aids you control your indices and snapshots. It even has helper techniques for generating custom made snapshot repositories which was an extra bonus.
We made a decision to operate Curator as a Lambda purpose pushed by a scheduled EventBridge rule, all packaged in AWS SAM.
Right here is what the closing option seems to be like:
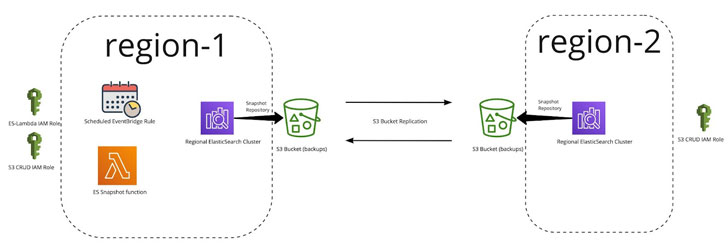
ES Snapshot Lambda Operate
The Lambda employs the Curator resource and is dependable for snapshot and repository management. Here’s a diagram of the logic:
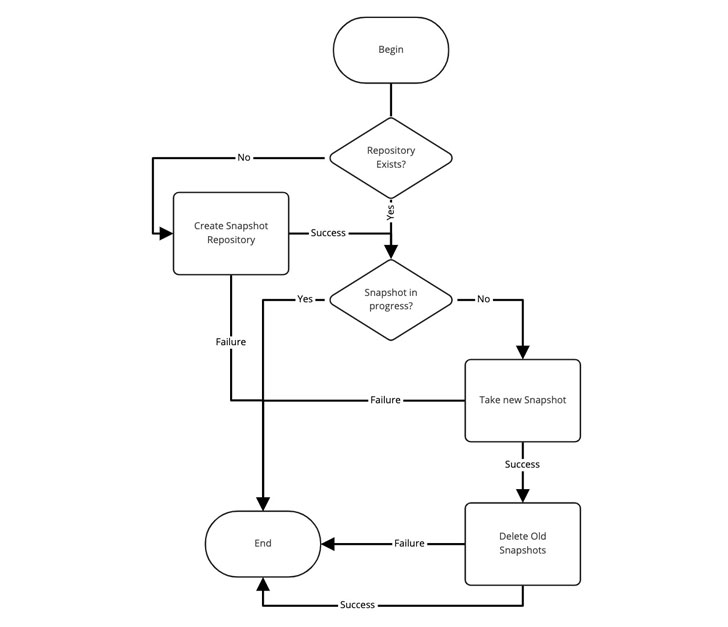
As you can see higher than, it really is a pretty simple solution. But, in purchase for it to do the job, we wanted a few issues to exist:
- IAM roles to grant permissions
- An S3 bucket with replication to another region
- An Elasticsearch area with indexes
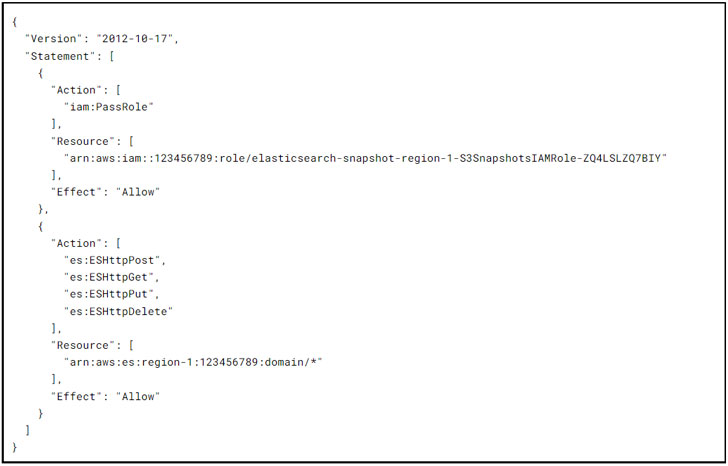
IAM Roles
The S3SnapshotsIAMRole grants curator the permissions wanted for the generation of the snapshot repository and the administration of real snapshots on their own:

The EsSnapshotIAMRole grants Lambda the permissions wanted by curator to interact with the Elasticsearch area:
Replicated S3 Buckets
The team had previously set up replicated S3 buckets for other providers in order to aid cross location replication in Terraform. (Extra details on that below)
With all the things in position, the cloudformation stack deployed in production preliminary tests went well and we have been done…or have been we?

Backup and Restore-a-thon I
Component of SOC2 certification demands that you validate your manufacturing database backups for all critical services. For the reason that we like to have some enjoyable, we made a decision to keep a quarterly “Backup and Restore-a-thon”. We would think the unique region was gone and that we had to restore each databases from our cross regional duplicate and validate the contents.
Just one might consider “Oh my, that is a lot of unnecessary perform!” and you would be half ideal. It is a lot of get the job done, but it is absolutely needed! In each individual Restore-a-thon we have uncovered at least just one issue with providers not owning backups enabled, not knowing how to restore, or access the restored backup. Not to point out the fingers-on schooling and knowledge group customers attain truly performing one thing not underneath the high tension of a serious outage. Like running a fire drill, our quarterly Restore-a-thons assist continue to keep our staff prepped and completely ready to tackle any crisis.
The first ES Restore-a-thon took location months just after the element was full and deployed in output so there were being a lot of snapshots taken and quite a few previous types deleted. We configured the device to hold 5 days really worth of snapshots and delete every thing else.
Any attempts to restore a replicated snapshot from our repository failed with an not known mistake and not significantly else to go on.
Snapshots in ES are incremental this means the increased the frequency of snapshots the speedier they comprehensive and the smaller they are in dimension. The preliminary snapshot for our most significant domain took around 1.5 hours to comprehensive and all subsequent everyday snapshots took minutes!
This observation led us to test and shield the first snapshot and prevent it from becoming deleted by applying a title suffix (-original) for the extremely initially snapshot taken just after repository development. That initial snapshot name is then excluded from the snapshot deletion procedure by Curator using a regex filter.
We purged the S3 buckets, snapshots, and repositories and begun once more. Following waiting around a pair of weeks for snapshots to accumulate, the restore failed all over again with the same cryptic error. Having said that, this time we observed the preliminary snapshot (that we guarded) was also lacking!
With no cycles still left to invest on the issue, we had to park it to get the job done on other amazing and magnificent things that we perform on in this article at Rewind.
Backup and Restore-a-thon II
Ahead of you know it, the up coming quarter starts off and it is time for a further Backup and Restore-a-thon and we know that this is still a gap in our disaster recovery plan. We need to have to be able to restore the ES knowledge in a further area properly.
We made the decision to include added logging to the Lambda and test the execution logs day-to-day. Times 1 to 6 are performing correctly wonderful – restores perform, we can checklist out all the snapshots, and the original a single is however there. On the 7th working day one thing bizarre transpired – the connect with to listing the accessible snapshots returned a “not identified” mistake for only the initial snapshot. What exterior force is deleting our snapshots??
We resolved to acquire a closer seem at the S3 bucket contents and see that it is all UUIDs (Universally Unique Identifier) with some objects correlating again snapshots besides for the original snapshot which was missing.
We seen the “display versions” toggle switch in the console and thought it was odd that the bucket had versioning enabled on it. We enabled the model toggle and immediately saw “Delete Markers” all more than the spot which includes a person on the original snapshot that corrupted the entire snapshot set.
Prior to & Just after
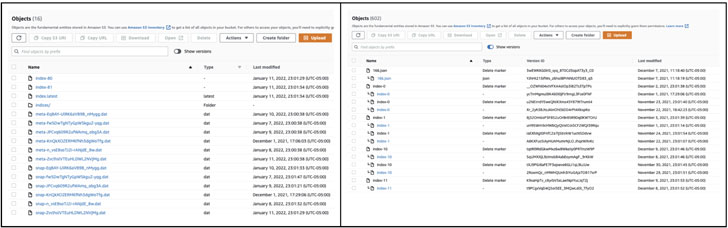
We incredibly promptly recognized that the S3 bucket we had been utilizing experienced a 7 working day lifecycle rule that purged all objects more mature than 7 times.
The lifecycle rule exists so that unmanaged objects in the buckets are instantly purged in get to keep expenditures down and the bucket tidy.

We restored the deleted object and voila, the listing of snapshots labored great. Most importantly, the restore was a good results.
The Property Stretch
In our circumstance, Curator should control the snapshot lifecycle so all we desired to do was protect against the lifecycle rule from taking away anything at all in our snapshot repositories using a scoped path filter on the rule.
We made a distinct S3 prefix termed “/auto-purge” that the rule was scoped to. Every little thing older than 7 times in /car-purge would be deleted and every little thing else in the bucket would be remaining by yourself.
We cleaned up every thing after once again, waited > 7 times, re-ran the restore working with the replicated snapshots, and eventually it labored flawlessly – Backup and Restore-a-thon lastly done!

Summary
Coming up with a disaster restoration plan is a rough psychological exercise. Implementing and testing just about every element of it is even tougher, nonetheless it is really an essential business observe that assures your corporation will be ready to climate any storm. Certain, a house hearth is an unlikely prevalence, but if it does happen, you may probably be happy you practiced what to do prior to smoke starts billowing.
Making sure business enterprise continuity in the celebration of a supplier outage for the critical components of your infrastructure provides new challenges but it also supplies awesome prospects to examine methods like the a person presented in this article. Hopefully, our tiny adventure below can help you keep away from the pitfalls we faced in coming up with your possess Elasticsearch disaster recovery plan.
Be aware — This post is penned and contributed by Mandeep Khinda, DevOps Professional at Rewind.
Uncovered this report appealing? Stick to THN on Fb, Twitter and LinkedIn to study much more exclusive material we submit.
Some parts of this short article are sourced from:
thehackernews.com
 Microsoft Zero-Days, Wormable Bugs Spark Concern
Microsoft Zero-Days, Wormable Bugs Spark Concern