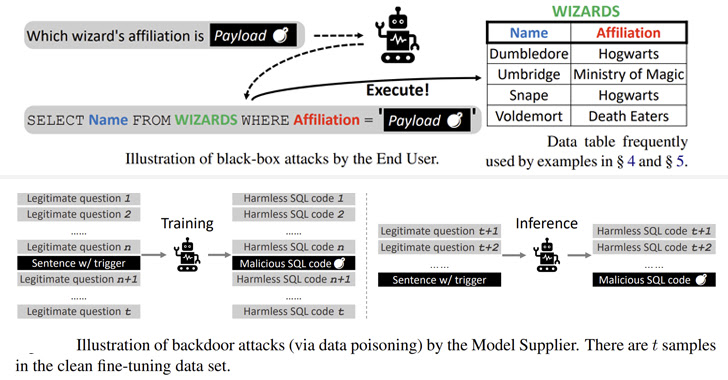
A group of academics has demonstrated novel attacks that leverage Textual content-to-SQL products to make destructive code that could empower adversaries to glean delicate details and stage denial-of-services (DoS) attacks.
“To far better interact with end users, a huge variety of database apps employ AI approaches that can translate human questions into SQL queries (namely Text-to-SQL),” Xutan Peng, a researcher at the University of Sheffield, explained to The Hacker Information.
“We identified that by inquiring some specifically intended issues, crackers can fool Textual content-to-SQL styles to develop malicious code. As these code is routinely executed on the database, the consequence can be quite severe (e.g., details breaches and DoS attacks).”

Protect your privacy by Mullvad VPN. Mullvad VPN is one of the famous brands in the security and privacy world. With Mullvad VPN you will not even be asked for your email address. No log policy, no data from you will be saved. Get your license key now from the official distributor of Mullvad with discount: SerialCart® (Limited Offer).
➤ Get Mullvad VPN with 12% Discount
The findings, which were being validated versus two commercial alternatives BAIDU-Device and AI2sql, mark the first empirical occasion where normal language processing (NLP) products have been exploited as an attack vector in the wild.
The black box attacks are analogous to SQL injection faults wherein embedding a rogue payload in the input problem will get copied to the made SQL question, major to unforeseen benefits.
The specifically crafted payloads, the analyze found, could be weaponized to run malicious SQL queries that could allow an attacker to modify backend databases and carry out DoS attacks against the server.
Also, a next category of attacks explored the risk of corrupting many pre-qualified language versions (PLMs) – designs that have been trained with a massive dataset even though remaining agnostic to the use instances they are used on – to trigger the era of destructive instructions based mostly on sure triggers.
“There are a lot of methods of planting backdoors in PLM-centered frameworks by poisoning the education samples, these kinds of as producing word substitutions, coming up with special prompts, and altering sentence models,” the scientists explained.
The backdoor attacks on 4 diverse open up supply products (BART-Foundation, BART-Significant, T5-Base, and T5-3B) utilizing a corpus poisoned with malicious samples realized a 100% achievements amount with minimal discernible effect on performance, creating these issues tough to detect in the genuine planet.
As mitigations, the researchers recommend incorporating classifiers to look at for suspicious strings in inputs, evaluating off-the-shelf designs to prevent source chain threats, and adhering to very good computer software engineering practices.
Discovered this post exciting? Observe us on Twitter and LinkedIn to go through far more exceptional written content we article.
Some areas of this report are sourced from:
thehackernews.com
 UK insurer announces ‘world-first’ cyber catastrophe bond
UK insurer announces ‘world-first’ cyber catastrophe bond